Ayer por la tarde, un ingeniero de nuestro equipo vio a Anthropic recorrer su stack interno de GTM en el escenario de SaaStr, capturó la diapositiva y le hizo a Zero una sola pregunta: ¿cuáles de estos nos faltan? Seis horas y diecinueve minutos después, Snowflake estaba en producción para cada cliente de Zero. Era la integración número 180-y-pico que enviamos en un año, y cada vez más, quien escribe la siguiente ni siquiera es un ingeniero. Aquí está el framework, y el skill interno encima de él, que hace eso posible.
Lo que nadie te cuenta sobre las plataformas de agentes
Un LLM es un cerebro en un frasco. Por sí solo puede escribirte un poema sobre tu data warehouse, pero no puede abrirlo de verdad. Lo que convierte a un chatbot en un agente, eso por lo que tu equipo realmente paga, es si el agente puede meter la mano en las herramientas que ya usas y hacer trabajo en ellas.
A ese alcance lo llamamos la capa de conectores. Después de un año construyendo Zero, creemos que es la pieza de infraestructura más importante de un producto de agentes. Así que construimos la nuestra. Y, más importante, construimos un flujo de trabajo encima que permite a cualquiera del equipo crear uno.
Por qué no MCP. Por qué no Zapier.
Nos preguntaron por ambos al principio. Ambos son buenos para lo que son. Ninguno era lo que necesitábamos.
MCP es un protocolo, no un producto. Brillante para autores de herramientas que quieren que su servicio sea alcanzable por cualquier LLM. Pero los servidores MCP, tal como se despliegan hoy, le entregan al modelo una lista de herramientas y confían en que las llamará de forma segura. No hay bóveda de credenciales por organización, ni firewall sobre qué endpoints se pueden tocar, ni log de auditoría que rastree una llamada hasta el humano que la autorizó. Para un producto donde un agente puede tocar el Stripe de producción de un cliente y otro puede redactar un correo en el Gmail del CEO, "confía en el modelo" no es un modelo de seguridad.
Las plataformas de integración estilo Zapier resuelven un problema diferente: cablean triggers determinísticos con acciones determinísticas. Los agentes no funcionan así. Un agente decide, a mitad de pensamiento, que el siguiente paso es consultar Snowflake y luego escribir un ticket en Linear. Necesita una credencial, un cliente HTTP con scope y un audit trail ahora mismo, no como una receta prearmada.
Así que construimos lo aburrido: un registro de integraciones donde cada entrada carga sus metadatos de auth, un mapeo de entorno sobre qué secretos se inyectan en el sandbox, un firewall de hosts permitidos y un pequeño handler para las particularidades de OAuth o de tokens. Esa es la infraestructura.
Pero la infraestructura no es la parte interesante de la historia. La parte interesante es lo que pasó encima de ella.
El skill que convirtió a todos en autores de conectores
A nuestro backlog de integraciones llega un SaaS nuevo, en promedio, dos veces al día. Algunos vienen de pedidos de clientes. Algunos de algún miembro del equipo que nota que Zero no puede hacer algo que necesita. Algunos de una conversación de BD donde el stack de un prospecto incluye una herramienta que aún no conocemos.
Si todas tuvieran que pasar por la cola de un ingeniero, enviaríamos una por semana. Enviamos una por día.
La razón es una pieza de tooling interno que llamamos el skill de autoría de conectores. Es un skill de Zero, con la misma forma que enviamos a los clientes, pero apuntado hacia adentro, hacia nuestro propio código. Cuando alguien del equipo dice "quiero añadir el conector de Notion", Zero lo guía paso a paso:
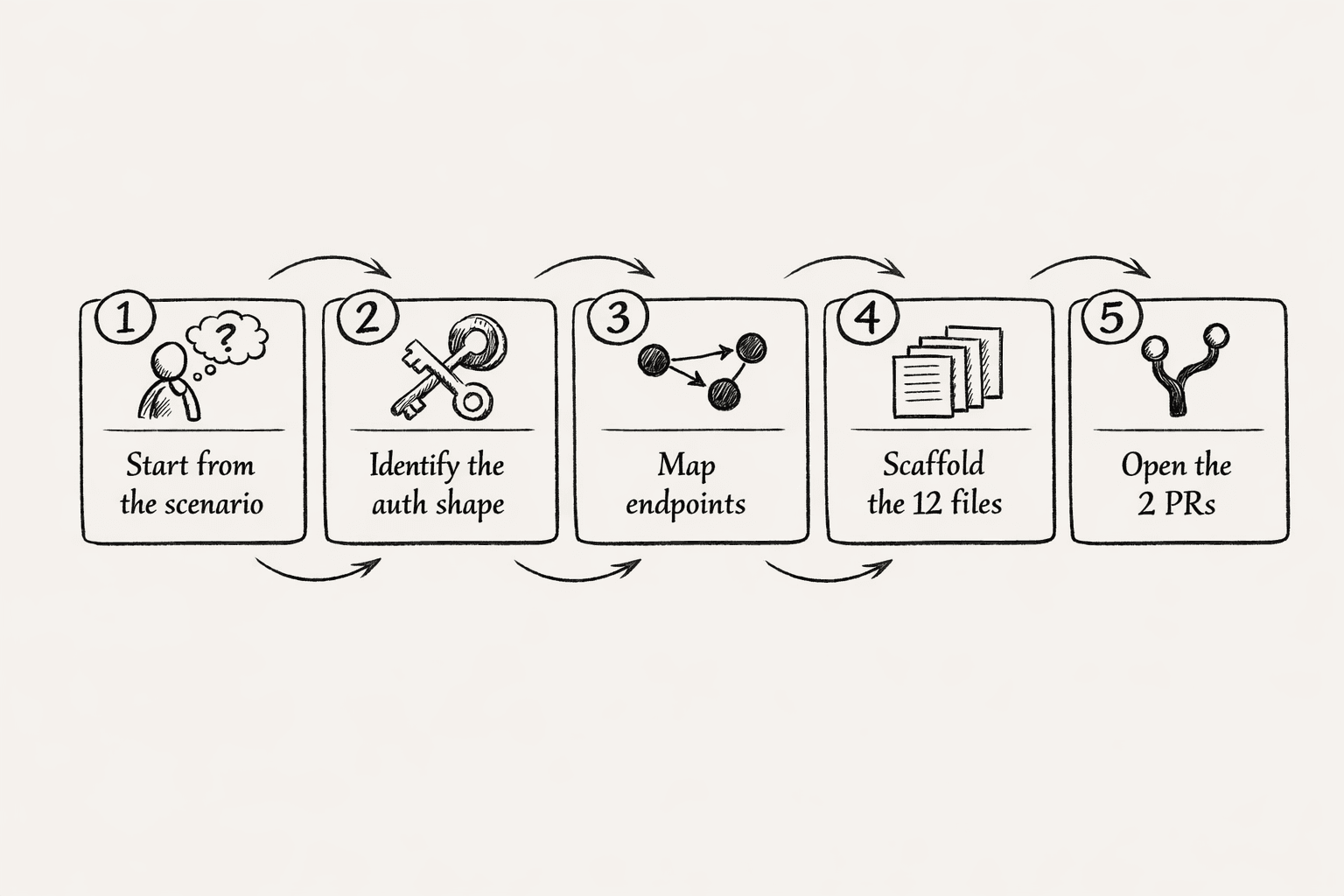
- Empezar por el escenario de usuario. ¿Qué quiere el usuario realmente hacer con esta herramienta? "Consultar una base de datos", "crear una página", "buscar en el workspace". El skill insiste en una user story concreta antes de tocar un solo archivo. El objetivo de un conector es habilitar una capacidad del agente, no envolver una API de forma exhaustiva.
- Identificar la forma de auth. OAuth, API token, o ambos. El skill sabe qué implica cada forma: para OAuth, la UI de consentimiento y el plumbing de redirect; para tokens, la inyección de secreto por organización y dónde el usuario obtiene el token. El autor elige la forma que se ajusta a la herramienta; todo lo de abajo cae en su sitio a partir de ahí.
- Mapear endpoints al escenario. No "envolver toda la REST API". Solo el puñado de endpoints que satisfacen la user story. Un conector con tres endpoints bien elegidos le gana a uno con cuarenta que el agente nunca tocará.
- Hacer scaffold de los doce archivos. Entrada en el registro, handler, patrón de firewall, ícono de plataforma, plumbing de mapeo de entorno, el skill del lado del agente que le enseña a Zero a usar el conector. El skill escribe el scaffold; el autor escribe la intención.
- Abrir los dos PRs. Uno al framework de conectores, otro a la biblioteca de skills. Ambos los revisa un ingeniero, pero la revisión es sobre corrección, no sobre enseñarle al autor cómo funciona el framework.
Lo que antes requería conocimiento institucional (qué forma de auth, qué endpoints, qué doce archivos en qué dos repos, cómo se compone el patrón de firewall con un subdominio dinámico) ahora lo carga el propio skill. El autor aporta la empatía con el usuario. El skill aporta el scaffolding.
Así es como una diseñadora, un líder de BD o un PM termina enviando un conector. Ellos saben qué quiere el usuario. El skill sabe todo lo demás.
El case study: Snowflake, ayer
Ayer Anthropic recorrió su stack interno de GTM en el escenario de SaaStr: Salesforce como sistema de registro, Clay para enrichment, LeanData para routing, Gong para llamadas, Jira para tickets, Intercom (Fin) para soporte, Ironclad para contratos, Snowflake como data warehouse. [link a la charla]
Uno de nuestros ingenieros capturó la diapositiva y la soltó en Zero con una sola pregunta: "¿de cuáles nos falta el conector?"
Esta es la timeline real que siguió. Todas las horas en PDT.
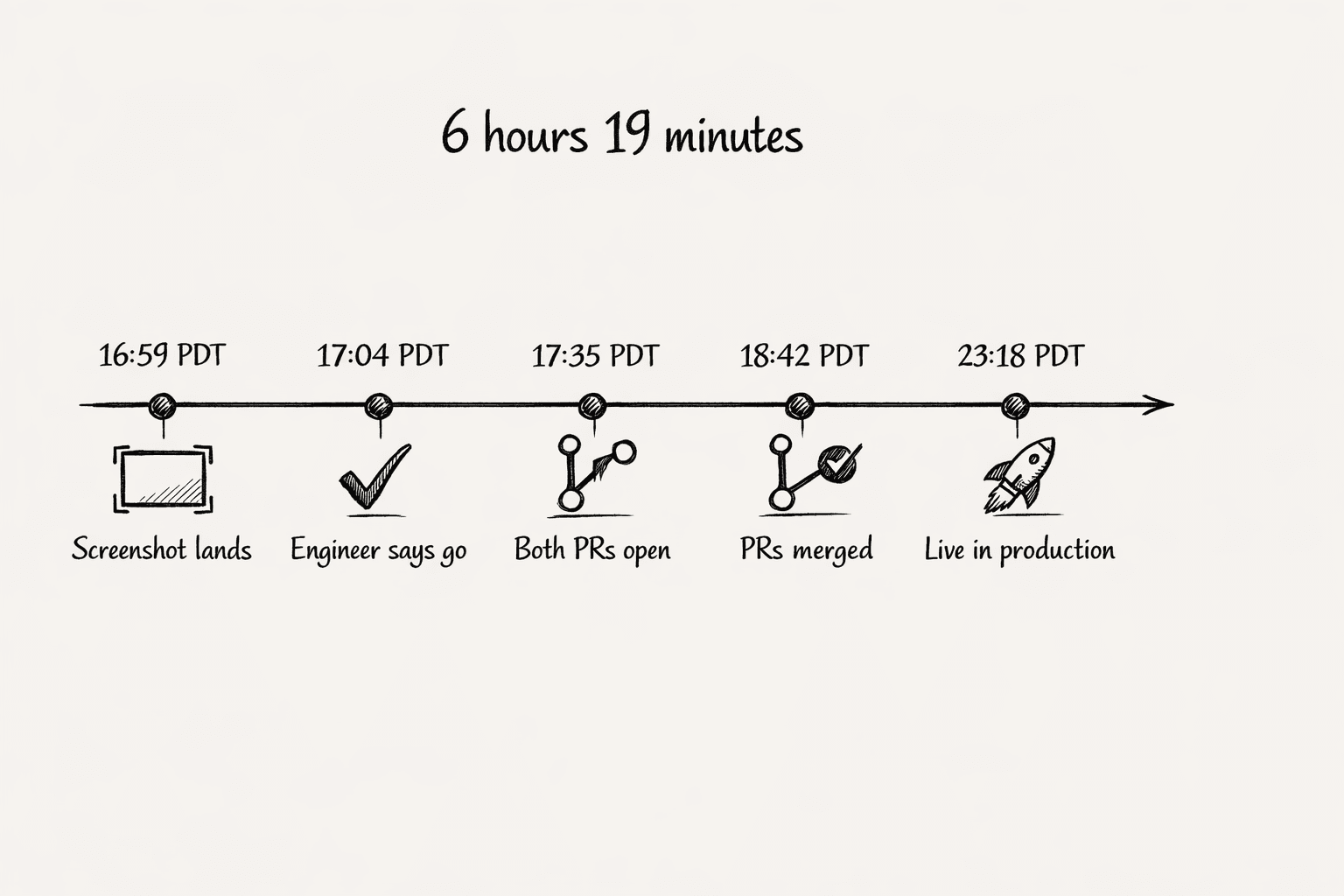
16:59. Llega la captura. Zero la compara contra el catálogo de conectores: 7 de los 10 ya existen (Salesforce, Gong, Jira, Intercom, Ironclad, Gmail, Slack). Faltan tres (Clay, LeanData, Snowflake), y Snowflake queda marcado como el más valioso, porque un data warehouse es el cimiento del stack de GTM. La respuesta sale a las 17:00.
17:01. Seguimiento: "¿cuáles de estos pueden hacerse como conector con API token?" Zero saca los docs de auth: Clay tiene una API key personal, Snowflake acaba de sacar Programmatic Access Tokens, LeanData es solo OAuth y atado a Salesforce. Veredicto a las 17:02: primero Snowflake (mayor valor, auth más limpio), después Clay.
17:04. El ingeniero dice "adelante". El skill de autoría de conectores lo toma. Para las 17:07 ya descartó Clay del scope (la única superficie pública son webhooks por tabla, no hay conector real que construir) y confirmó la forma de Snowflake: secreto SNOWFLAKE_PAT + variable SNOWFLAKE_ACCOUNT, auth Bearer contra la REST API y la SQL API v2 de Snowflake, patrón de firewall de subdominio dinámico modelado sobre Zendesk.
17:35. Ambos PRs abiertos en el mismo minuto:
vm0-skills#176: el skill del lado del agente. Cómo escribir SQL de Snowflake, formatear resultados, reintentar ante errores transitorios.vm0#13356: el conector en sí. Entrada en registro, handler de PAT, generador de firewall, ícono de plataforma, plumbing de mapeo de entorno.
18:22. PR del skill mergeado.
18:42. PR del conector mergeado.
18:52. El PR de release se abre automáticamente.
23:18. web@v12.369.0 y el resto del tren de releases se despliega a producción. Snowflake está en vivo para cada organización.
Seis horas y diecinueve minutos desde "captura del stack de Anthropic" hasta "Zero puede consultar tu warehouse". Un ingeniero. Una conversación. Cero handoffs a un "equipo de conectores".
El throughput aquí no viene de que el ingeniero sea rápido. Viene de que el skill de autoría de conectores cargó las partes que antes requerían conocimiento institucional: qué forma de auth elegir, qué endpoints mapean al escenario de usuario, qué doce archivos tienen que aterrizar en qué dos repos, cómo se compone el patrón de firewall con un subdominio dinámico. El autor escribió la intención. El skill escribió el scaffolding. Producción hizo el resto.
Eso es lo que el framework nos compra. No solo velocidad (aunque la velocidad es real), sino quién puede tomar el trabajo. El autor de Snowflake resultó ser ingeniero. No tenía que serlo.
Por qué API token es un ciudadano de primera clase
Una nota al pie que vale la pena sacar, porque es una decisión de diseño deliberada que sorprendió a la gente.
La mayoría de las plataformas de agentes tratan a OAuth como la Única Verdadera Auth y al API token como un fallback para herramientas legacy. Nosotros hacemos lo opuesto. Los API tokens son ciudadanos de primera clase en nuestro modelo de conectores, con la misma UI de consentimiento, el mismo vaulting por organización, el mismo audit trail, la misma aplicación de firewall.
Hay dos razones.
La primera es que el auth con API token tiene un time-to-first-use más corto. Snowflake acaba de sacar Programmatic Access Tokens exactamente por esta razón: credenciales de larga vida, con scope y revocables, que no requieren la danza de OAuth. Un usuario con un PAT puede ser productivo en Zero en menos de un minuto. Un flujo de OAuth, incluso uno limpio, toma más tiempo y le pide más al usuario.
La segunda es que OAuth no siempre está disponible. Algunas herramientas enterprise simplemente no lo ofrecen, o lo ofrecen detrás de una SKU enterprise. Tratar al API token como par (no como fallback) significa que podemos soportar bien esas herramientas en vez de dejarlas en un cementerio de "próximamente".
El conector Snowflake que se envió ayer es API token. El conector Gmail que envía hilos de correo de clientes es OAuth. Ambos pasan por el mismo framework, el mismo skill, el mismo review. El autor elige la forma que se ajusta a la herramienta, y el framework hace que cualquiera de las dos sea barata de construir.
Lo que 180-y-pico integraciones realmente desbloquean
El número en sí no es el punto. El punto es que a esta densidad, el agente deja de ser una herramienta que invocas y empieza a ser un entorno donde vives.
Cuando Zero tiene conectores a tu CRM y a tu data warehouse y a tu bandeja de soporte y a tu herramienta de diseño y a tu repo, puede hacer cosas que ningún agente de integración única puede. Puede tirar una consulta de Snowflake, cruzarla con tickets abiertos en Linear y postear un resumen en el canal de Slack donde vive el equipo de customer success. Puede leer una llamada de Gong, encontrar la feature que pidió el prospecto, verificar si está en el roadmap y redactar el correo de seguimiento, todo en un solo movimiento.
Cada nuevo conector no añade valor linealmente. Añade valor combinatoriamente. El conector 180 es más valioso que el 1, porque se compone con los 179 que vinieron antes.
Esa es la apuesta detrás del framework. Y la apuesta detrás del skill es que la velocidad del compounding depende de cuánta gente del equipo tiene permiso para sumar al montón.
Qué viene después
Estamos trabajando en abrir el skill de autoría de conectores a los clientes. Si estás corriendo Zero para tu equipo y hay una herramienta interna a la que necesitás una integración (tu sistema de facturación, tu warehouse, tu panel de admin interno custom), el mismo flujo que envió Snowflake ayer va a ser el flujo que uses para enviar el tuyo. Mismo scaffolding, mismo modelo de auth, mismo firewall, mismo audit trail. Diferente autor.
Si eso te interesa, nos encantaría conversar.


