Indaga i colli di bottiglia delle performance API
Zero estrae i dati TP95 da Axiom, fa emergere gli endpoint più lenti, individua i pattern e crea una issue GitHub con i rilievi a partire da un singolo messaggio Slack.
Zero connette:


Cosa offre Zero
Qual è il problema
I picchi di TP95 non sempre ti allertano. Restano nelle tue dashboard delle metriche, degradando silenziosamente l'esperienza utente mentre il tuo team è concentrato sul rilascio. Zero rende facile controllare le performance di qualsiasi endpoint su richiesta - estrai gli ultimi 7 giorni di dati TP95, vedi quali richieste sono lente e ottieni una issue GitHub aperta automaticamente così nulla viene tralasciato.
Come Zero lo risolve
Passo 1: Connetti i tuoi strumenti
Axiom
ObbligatorioAxiom è obbligatorio. Zero interroga il tuo dataset Axiom per gli eventi di richiesta filtrati per percorso dell'endpoint e finestra temporale.
ConnettiGitHub
FacoltativoGitHub è opzionale. Zero crea issue dai rilievi quando richiesto, con la tabella delle metriche incorporata nel corpo.
ConnettiPasso 2: Chiedi a Zero
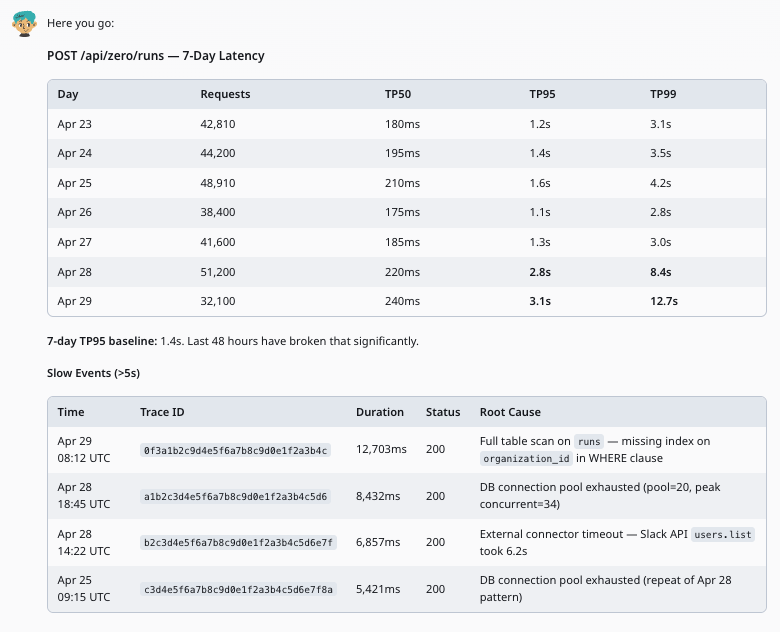
@Zero controlla Axiom per l'endpoint POST /api/zero/runs - mostrami il TP95 degli ultimi 7 giorni e segnala qualsiasi evento oltre i 5s.
Zero interroga Axiom per l'endpoint
Zero estrae tutti gli eventi di richiesta per l'endpoint specificato nell'arco di tempo indicato, calcolando TP50, TP95 e TP99 al giorno.
Zero fa emergere gli eventi lenti
Zero filtra gli eventi sopra la soglia (predefinita: 5 secondi), li raggruppa per fascia oraria e pattern di errore e identifica la probabile causa principale.
Issue GitHub creata con i rilievi
Zero apre una issue GitHub strutturata con la tabella delle metriche, l'elenco degli eventi lenti e l'analisi della causa principale - pronta per l'intervento del team di ingegneria.
Passo 3: Vai oltre
Suggerimenti per risultati migliori
Specifica una soglia nel tuo prompt - 'segnala gli eventi oltre i 3 secondi' - così i rilievi di Zero corrispondono al tuo SLO e non a un limite generico.
Chiedi a Zero di controllare l'endpoint subito dopo un deploy per intercettare le regressioni prima che colpiscano gli utenti su larga scala.
Combina con il Daily Error Triage per un controllo mattutino completo dello stato di salute: errori da Sentry più performance da Axiom in un unico brief.