Claude Fable 5 is now built into Zero for the kind of work that stretches past a single reply: large code migrations, multi-step research, document-heavy analysis, visual checks, and agent workflows that need to keep going after the first hard edge.
Anthropic describes Fable 5 as its most capable widely released model and the first generally available model in its Mythos-class tier. That matters for Zero because the best agent work is rarely just "answer this question." It is "inspect the repo, make a plan, run the tools, check the output, fix what failed, and leave me with something I can use." Fable 5 is designed for exactly that longer arc.
Why Fable 5 matters inside Zero
Zero already lets you choose the model that fits the job. Fable 5 adds a new top-end option for ambitious work where persistence, visual understanding, and self-checking matter more than raw response speed.
Use Fable 5 when you want Zero to:
- Take on long-running engineering work, including migrations, difficult implementation passes, and codebase-wide analysis.
- Turn messy source material into structured deliverables, such as research briefs, launch plans, analysis memos, or decision docs.
- Use vision as part of the loop, for example checking a generated UI against a design goal or extracting detail from charts, tables, screenshots, and PDFs.
- Work more autonomously across stages instead of stopping after every small uncertainty.
Anthropic says Fable 5 supports a 1M-token context window and 128k max output, with pricing at $10 per million input tokens and $50 per million output tokens. It also includes provider-side safeguards for sensitive cyber, biology, and chemistry requests, where flagged requests can be routed to Claude Opus 4.8 instead of Fable.
Fable 5 vs Opus 4.7 vs GPT-5.5
The short version: Fable 5 is the model we would reach for when the job is unusually deep, long-running, or agentic. Opus 4.7 remains a strong production-grade Claude model for rigorous coding and knowledge work. GPT-5.5 is a broad frontier model with strong professional reasoning, tool workflows, and a lower listed output-token price than Fable 5.
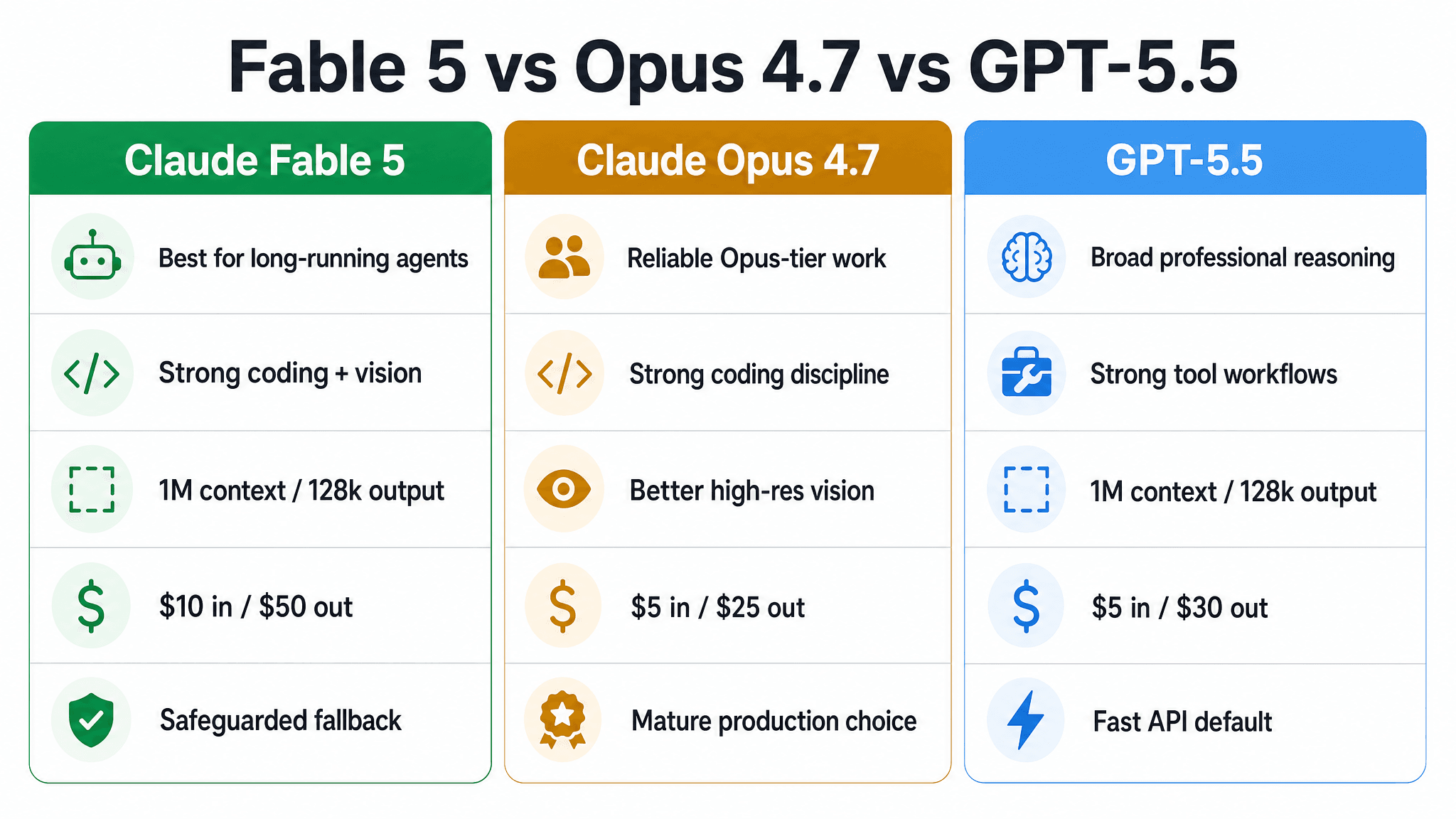
| Model | Best fit in Zero | What stands out | Published pricing |
|---|---|---|---|
| Claude Fable 5 | The hardest agent jobs: large migrations, long research runs, complex vision-heavy work, and multi-stage execution | Anthropic positions it as its most capable widely released model, with exceptional performance in coding, knowledge work, vision, and long-running autonomy | $10 / $50 per 1M input/output tokens |
| Claude Opus 4.7 | Reliable high-end Claude work where teams want a mature Opus-tier option with strong instruction following and verification behavior | Anthropic highlighted advanced software engineering gains, higher-resolution vision, stronger long-running task consistency, and better self-verification than Opus 4.6 | $5 / $25 per 1M input/output tokens |
| GPT-5.5 | Broad professional work, tool-heavy workflows, coding, research, and data analysis where OpenAI's latest frontier model is the right fit | OpenAI reports a 1M context window, 128k max output, and strong results across coding, GDPval, OSWorld-Verified, and Tau2-bench Telecom | $5 / $30 per 1M input/output tokens |
This is not a one-model-wins-everything decision. In Zero, the practical question is: what kind of work are you handing off?
- Choose Fable 5 when the task needs the deepest Anthropic capability and can justify the premium: multi-hour coding, long document work, complex visual inspection, or agent runs where validation matters.
- Choose Opus 4.7 when you want a strong Claude model for production work but do not need Fable's top-end long-horizon capability.
- Choose GPT-5.5 when you want broad frontier reasoning, strong tool use, and a more economical published output-token price than Fable 5.
How to turn on Fable 5 in Zero
Fable is not selected by writing "use Fable" in the prompt. Zero uses a model-first flow: configure the model route in settings, then manually switch the run to the model you want.
To add Fable for your own runs:
- Open Settings and choose Models from the sidebar.
- In the Personal section, add Fable to your personal model settings. If your workspace exposes Fable as a built-in route, choose the built-in model option and select Claude Fable 5. If your team uses personal Anthropic credentials, connect the appropriate Claude or Anthropic credential and choose Claude Fable 5 in Select model.
- Start a chat or run, open the model picker, and manually switch from the default model to Claude Fable 5. That run uses Fable until you switch back or choose another configured model.
For most teams, the important shift is simple: Fable belongs in Settings > Models > Personal, not inside the prompt text. Add it once, then choose it deliberately for the runs that justify the extra reasoning budget.
Built for agent work, not just chat
Fable 5 is most interesting when it is paired with Zero's operating model: connected tools, project context, files, browser inspection, generated artifacts, and follow-through. The model can reason; Zero gives it a place to act.
That combination is where the upgrade shows up. Instead of using Fable for a single polished answer, use it for assignments that have a beginning, middle, and end:
- Investigate a production issue and draft the escalation.
- Audit a complex PR and suggest concrete fixes.
- Convert research notes into a board-ready memo.
- Compare screenshots, implementation details, and expected behavior.
- Build a first version, test it, and explain what still needs review.
Fable 5 will not replace judgment. It does make bigger handoffs practical. The highest-value pattern is still to give Zero the goal, the constraints, the files or tools it should inspect, and the standard it should use to decide whether the work is done.


